It took a long time to get here … but finally, this story had to be told…
In 2015 YaCy had become a well-recognized and already mature search engine software. This platform was intended to be used by private persons but there was also a demand by professional users as well. Designed as a peer-to-peer software, the architecture had some flaws by design:
- no stable search: consecutive queries do not produce the same search result, not on one peer and never for different peers. If YaCy would have a stable search result that would contradict to censor-resistance.
- incompleteness: we distribute our search index to a set of remote peers and we don’t have any control over the lifetime of the storage of that index. This causes a bad recall.
- lacking speed: peer-to-peer search is meta-search - the retrieval process is only as fast as the slowest peer. If we do a time-out, we are lacking information and increasing incompleteness.
All these problems are ok if we insist on having a “freedom index” but for professional use, these problems must be solved. As the demand was there, I was trying to find a good concept for a full re-design!
In late 2015 I met Ilya Kreymer in San Francisco (check out his repository, its amazing!). He was a former employee of the Internet Archive and worked on a free version of the wayback machine: openwayback. He created numerous other warc-based tools and this told me that a re-design of YaCy should not only consider separated components but also should use standards as ‘glue’ between the parts of the software.
This convinced me that we should have a WARC middle-layer in a new YaCy architecture and re-use all these amazing tools. The new YaCy architecture could i.e. have a crawler archive which looks loke the internet archive of all crawled pages.
A Supercomputer Plattform Architecture
So I designed slides to advertise a redesign of YaCy, at this time called “Kaskelix”.

These components would be either constructed from recycled code from YaCy or they would consist of external, standardized software modules. This design contained also optional elements - like “Moderation”, “Add-On Content” which are not obligatory for the whole construction but would leave room for a commercial assignment.
To prove feasibility, I added the following to-do picture:
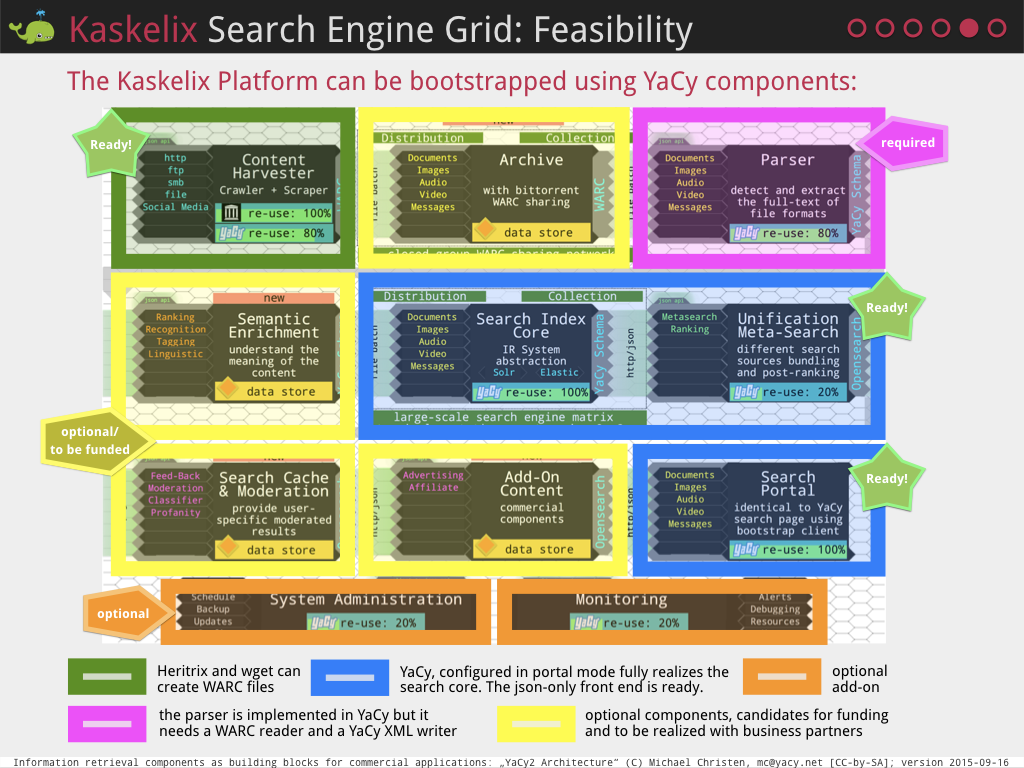
In January 2016, the OpenWebIndex initiative was started with a conference consisting mostly of members of the suma-ev. The idea was, that the OWI creates a large search index but not a search interface. Users of the OWI would have to create their own interface which would cause that comparison of the OWI with other search indexes could not happen on a user-experience level but only on scientific attributes.
YaCy Grid did still only exist as a concept, but I was sure that my approach was best suited for OWI. Unfortunately, it turned out that no software was ever developed for the OWI, the approach was purely political - at that time. We did not even reach the point where I was able to propose my architecture, which was most disappointing.
Implementation for a Business Partner
At the end of 2016, I actually found a business partner to implement some of the proposed components.
The architecture required an orchestration element which I called (ironically) MCP - “Master Connect (sic!) Program”. It also required a queueing mechanism which provided interfaces and scaling to the other grid elements.
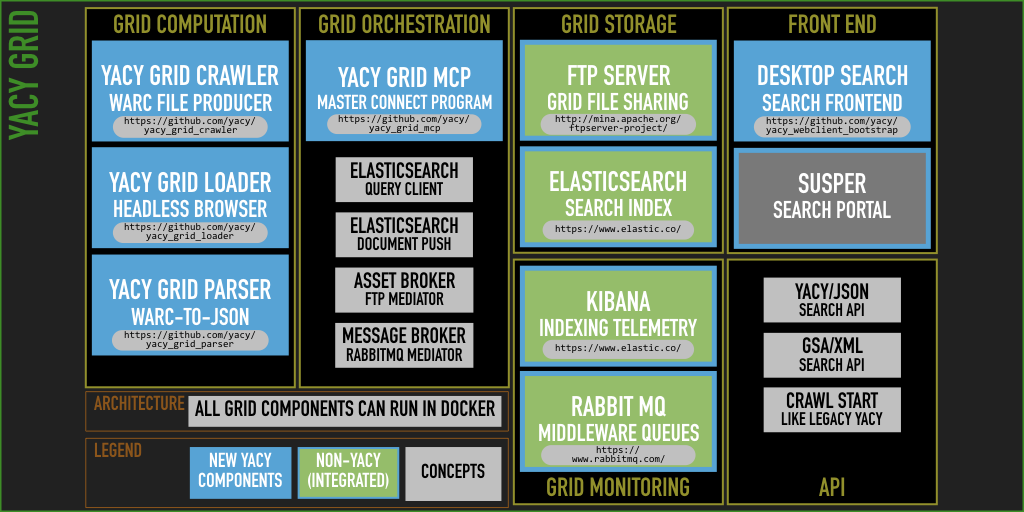
The following modules had been implemented for YaCy Grid:
- yacy_grid_mcp - grid orchestration. This software runs not only as daemon once in the grid, but it is also deeply integrated into the crawler, parser, loader and search element as git submodule. The MCP also includes a client to elasticsearch and acts as an indexing client for the grid.
- yacy_grid_crawler - crawler, which includes the crawl start servlet, host-oriented crawling balancing and filter logic for the crawl jobs.
- yacy_grid_loader - loader and headless browser. As of today, many (maybe mostly) web pages have not any more static content and content is loaded dynamically. As headless browser loading of web content is very complex, this component must be scalable.
- yacy_grid_parser - the YaCy Parser as it is implemented in “legacy” YaCy. We have an extremely rich metadata schema in YaCy and YaCy Grid inherits this schema.
- yacy_grid_search - the query parser and search back-end API for search front-ends. In the fashion of stateless microservices, this component can be scaled up according to the load on the search front-end.
- yacy_webclient_bootstrap - a demonstration search client that looks exactly the same as the in-legacy-YaCy built-in search front-end.
These parts must be combined with the following standard software:
- elasticsearch - instead of solr, YaCy Grid now uses elasticsearch as a search index
- kibana - dashboards for monitoring
- RabbitMQ - Queues for high-performance computing
- an FTP server - storage for WARC and flat-index files
Creating a search front-end for YaCy was also part of Google Summer of Code within the FOSSASIA Community - this created the following component:
- susper.com - a Google - look-alike Search Interface
All together in one picture:
Going Online in a Cloud-Hosted Kubernetes Cluster
A huge YaCy Grid installation went online at the beginning of 2018: Our partner who is running YaCy Grid for http://land.nrw uses a Kubernetes Cloud hosting for YaCy Grid Docker containers:
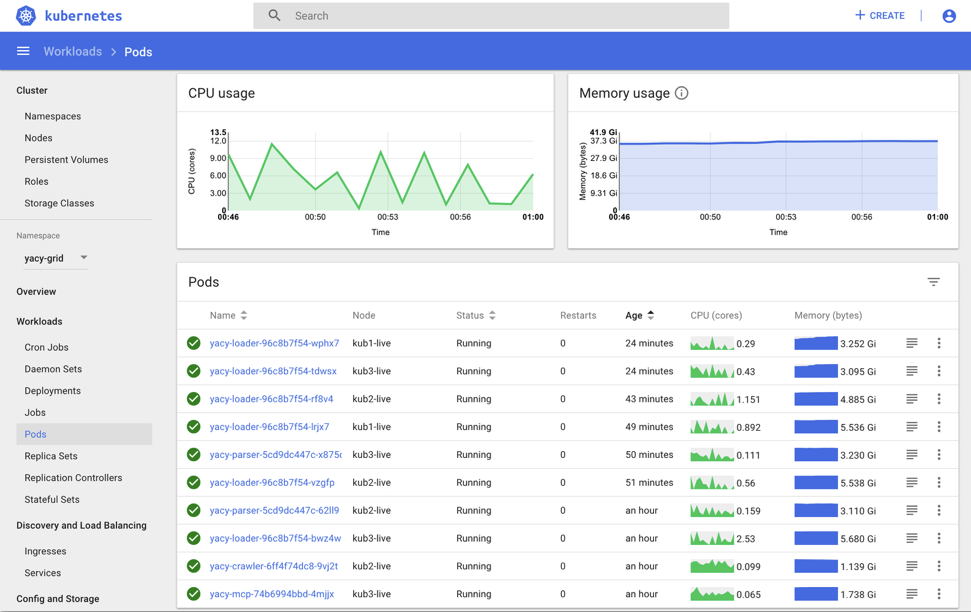
This provides a search index for the public administration documents and web pages of all communities (cities, villages, more than 1000) in the state of NRW/Germany.
We can monitor crawling behavior with kibana:

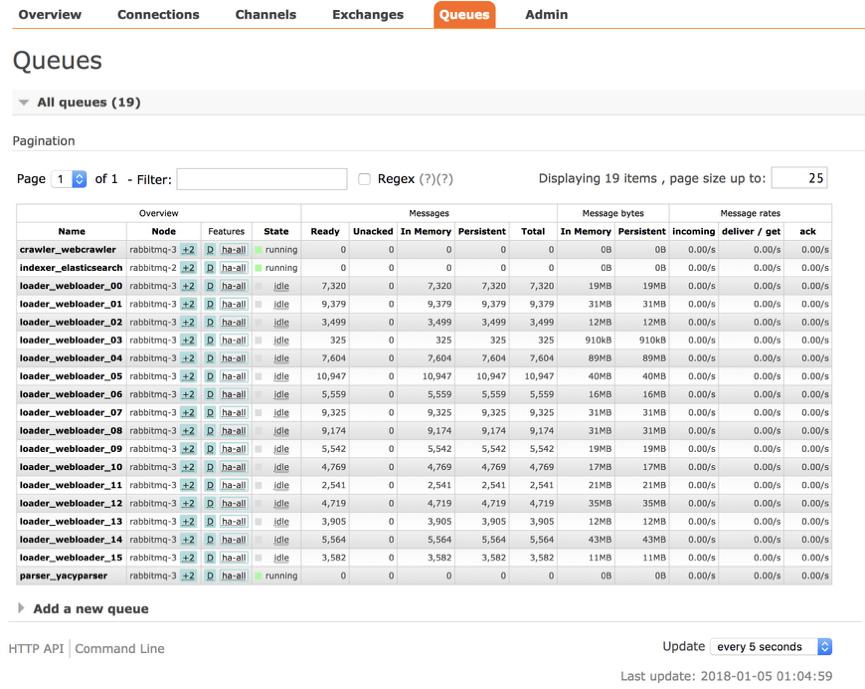
The load status of crawl queues and the queues of other grid components can be monitored with the dashboard of RabbitMQ:
YaCy Grid: A Scalable Search Appliance
As YaCy does not only provide a rich, opensearch-based search API but also an implementation of the Google Search Appliance XML API. That means, YaCy Grid may be a drop-in replacement of existing GSA user. As Google abandoned the GSA, users should switch to YaCy Grid.
With YaCy Grid we achieved finally:
- index stability - all search results for the same query are the same
- completeness - we can find everything that was crawled
- speed - this construction provides unlimited scaling: for crawling, indexing and for search.
The story is now still going on:
- more monitoring features and operational support (like re-crawling of failed loadings) is currently being developed for YaCy Grid
- we should develop a concept to integrate (or join) YaCy Grid with (the old) “legacy YaCy”.
- The OpenWebIndex initiative has new people on board and we are currently trying to integrate one part (yacy_grid_parser) of YaCy Grid into the OWI architecture.
- we need documentation. Creating a platform for documentation is now required…
To be continued…
If you like this story then you are invited to share your ideas in the comments! It is a huge challenge to join old and new YaCy components towards a better platform: would you like to contribute? What can be done by the community? Are you a professional user of the old YaCy software and would you like to switch to YaCy Grid?