I had an issue bootstrapping YaCy v.1.925/10082. According to the log, the new Solr version doesn’t accept the “old” Index Data Files from Solr version 7.7.3. Do I need to dump the whole Index via the Export feature and put it in /yacy/DATA/SURROGATES/in on the new YaCy release or is there a smoother way for an Index transition to Solr 8.8.1?
Thank you very much. It would be very great if the step via the export and import isn’t necessary because the PCIe SSD I’m using for YaCy has “only” 70 petabytes of I/O lifespan (MTBF) and 30 terabytes of I/O per week isn’t a rarity when operating a peer with the largest Index in Freeworld (I’m continuously recrawling very old Index entries, too).
I just commited changes that moves YaCy latest git version into a situation where it can start up again. There were many more dependency and configuration problems for solr 8 but it works now with that.
Sad to say that there is currently no automatic migration of indexes… Here is what you must do:
click on the “Export” button (leave all other settings as it is by default, export as json)
let it run and it will create a (large) single dump file in /DATA/EXPORT/
If you loaded a newer version already, don’t worry, the original 6.6er index files are not touched and not removed. Just move the DATA folder to an older YaCy version and the old index is still there.
I will make sure that this will can be imported with the solr 8.8.1 version.
Sorry for inconveniences, but I researched for solr-embeded tools but could not find one that migrates from 6.6 to 8.8.
Sad to say that there is currently no automatic migration of indexes
No problem, I’m using an old SAS-HDD with good average access time for the dump and the restore. Is the JSON export method more powerful than the XML one?
Cicero:index stefan$ ls -S -lah
total 8001171072
-rw-r--r-- 1 user staff 1.2T Nov 15 16:48 _1nkhb.fdt
-rw-r--r-- 1 user staff 381G Oct 23 06:47 _1nkhb_Lucene50_0.pos
-rw-r--r-- 1 user staff 260G Nov 15 09:41 _1nkhb_Lucene54_0.dvd
The whole Solr data directory has 3,6 TB. Well, that would take a few weeks I guess
oh wow das is not good. Looks like I should do some performance enhancements on the export process. But then - there would be the need to backport that. Hm.
I could try to increase the process priority if you can tell me the filename of the Java class. This boosted the performance at another workflow (recrawl the whole index) remarkably.
ich hab immer noch null Ahnung vom Programmieren Ich bewundere das weiterhin was du da machst.
Ich meine natürlich den Thread hab in der RecrawlBusyThread.java einen String gefunden
this.setPriority(Thread.MAX_PRIORITY);
Seitdem ich das auf MAX gesetzt habe, sind 200 GB Traffic/Woche beim recrawlen keine Seltenheit mehr Kann ich die Priorität von dem Index Export auch beeinflussen? Wenn ja: Wie heißt die Datei vom Quellcode?
also das ist gar keine schlechte Idee, ich habe jetzt genau diese Zeile mal in AbstractSolrConnector.java in Zeile 371 gepackt. Weiss noch nicht obs hilft…
Wenn ich mit meinem “Spezialpeer” (Endeavour) fertig mit exportieren bin (Er hat nur 40 Mio. Einträge, hiermit habe ich eine Open Source Intelligence Plattform gecrawlt) mache ich die Änderung auch mal im Quellcode der 1.924/10042 und exportiere dann damit die 206 Mio. Dokumente von dem Epistemophilia peer. Hab mir eine schnelle SCSI-Platte via AFP gemounted für den Dump, will die PCIe SSD für YaCy etwas schonen, die hat “nur” 70 PB bis MTBF und hab hab garantiert schon 20 PB verbraten weil ich immer so viele Crawl-Jobs habe und die Tiefe immer auf 5 stelle
disk3 ist die Festplatte für den Dump. Läuft recht flott dafür dass es keine SSD ist. Ich hab die Änderungen im Code auch so gemacht wie du geschrieben hattest und neu kompiliert. Ich freue mich auf die neue Version mit dem Sol 8.8.1. Vielen Dank für alles!
I had similar troubles migrating around 500GB. (For anyone brave who thinks to give a try: do not use IndexUpgraderTool | Apache Solr Reference Guide 8.8.2 unless you are ok to miss a few fields mostly dates, and have a few java exceptions in your logs for these incompatible fields.)
Next think I did, I setup a separate solr 7.7.1 instance and used that for export, thinking that export speed will be increased if solr is in a different process space. I also changed YaCy code to export xml with lz4 compression instead of gzip in order to speed up the export. (I didnt use json yet, let’s hope that produced xml will work I will revert in a few hours)
However @Orbiter I see the following thing during export (with gzip or lz4 or json or embedded solr, it does the same)
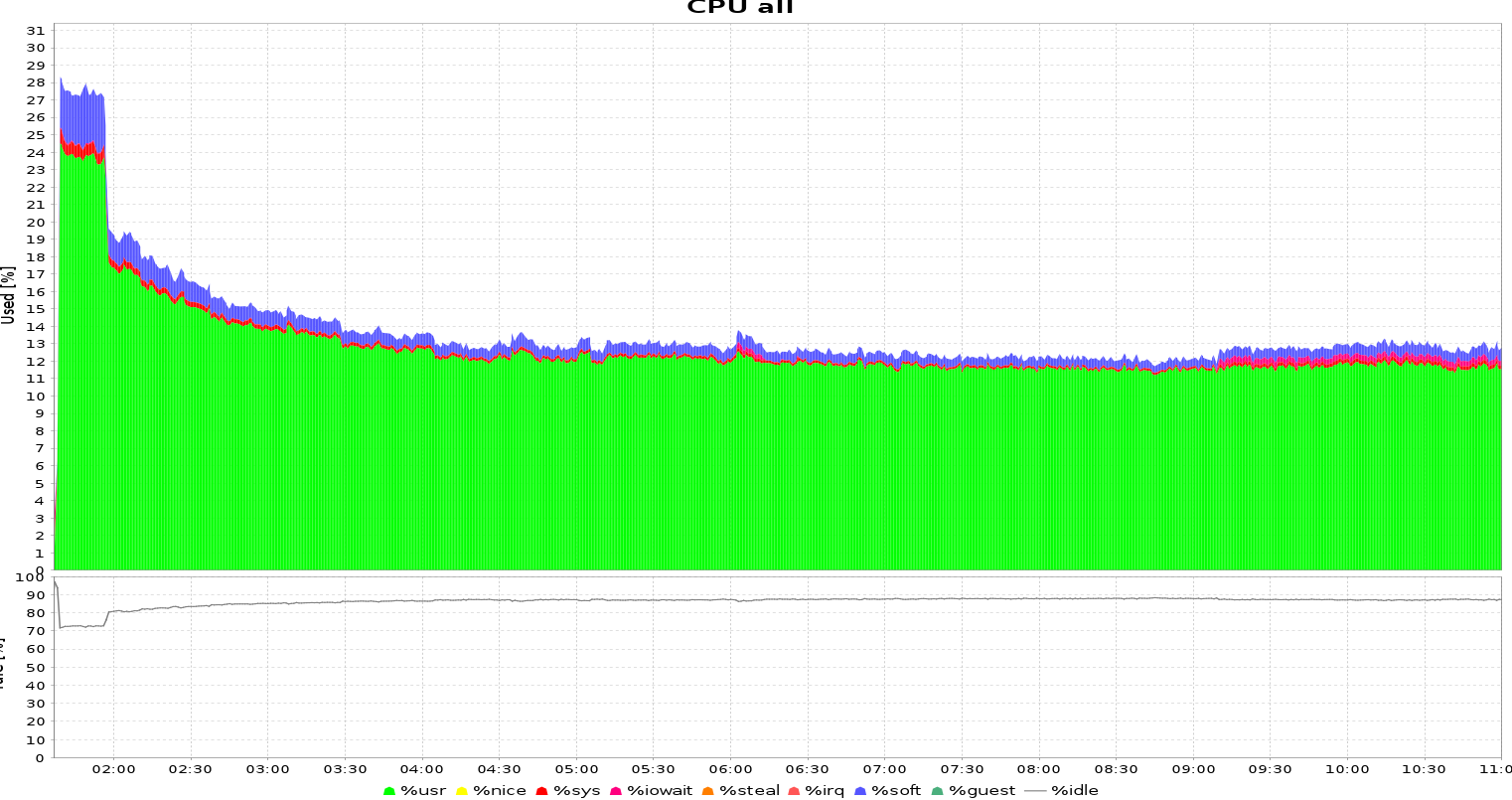
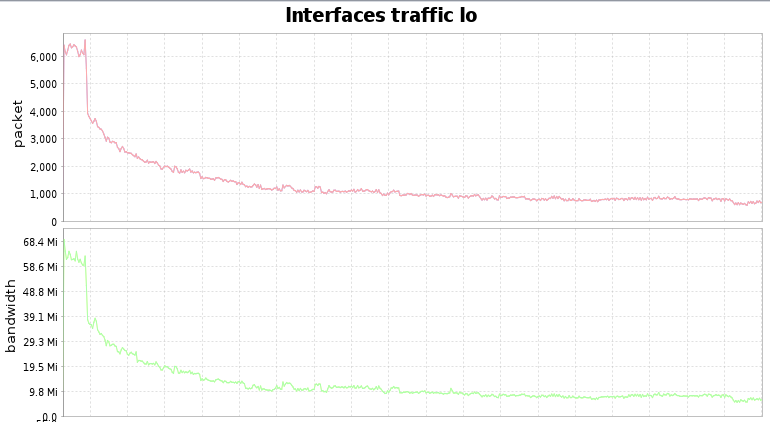
It runs fast for a 1-2 hours and then the performance degrades:
I had a look at your export code in Fulltext.java and especially in your BlockingQueue that you get from solr, but it doesnt seem obvious to me why it behaves like that. I dont have much solr experience so it’s not obvious why solr speed degrades over time during export. (the machine is a high performance yacy dedicated machine with 64GB ram and there is nothing else consuming resources)
Any ideas? If we manage to somehow improve the export speed, I can write a small migration tool to export from one solr and import to the other if anyone else finds this useful, since you froze your version at 1.924 and you can no longer publish changes.
Just for the record, if anyone wants to do the same, compressed xml export and import works without any issues as well. I successfully migrated my indexes to the 8.8.1 version.
Thank you for the analysis. Right now I don’t have an idea why the performance degrades. Maybe there is a connection between caching in solr - so it could be that performance degrades if caches in solr are all used up and performance is only dependent on IO. Then IO-performance stays the same, looks a bit like that.
 (I’m continuously recrawling very old Index entries, too).
(I’m continuously recrawling very old Index entries, too).
 Ich bewundere das weiterhin was du da machst.
Ich bewundere das weiterhin was du da machst.