Hello, Friends. Please tell me how not to collect all links to youtube, facebook, wikipedia and the like? I need the robot to take only the youtube page that the page being scanned links to. For example a page my-name.com links to a video on youtube, I need the robot to take only this one page with this video, and not scan the entire youtube and then the entire Internet along with Amazon…
Friends, please help ina with this. 
I think, in the admin area, set the crawl depth to 0 to index only the page associated with the URL entered, then Yacy will not crawl any additional pages. Set to depth = 1 Yacy will also index the pages associated with the links on the first page but go no further.
Personally, I almost never set depth to more than 1 or at most 2 as I only want to index very selected known URLs on specific topic areas and keep resource use to a minimum.
This should be able to be done using regex based blacklist rules, under Filter & Blacklists settings.
(or regex rule set at advanced crawler runs ?)
Unfortunately, regex is all but arcane whichcraft to me  , so i’m unable to provide the specific regex rules for your need.
, so i’m unable to provide the specific regex rules for your need.
Personally, i’ve simply blacklisted e.g facebook at domains level.
Maybe these could be of use to you? If only as tips at the least.
- https://regexlib.com/Search.aspx?k=youtube
- https://regexlib.com/Search.aspx?k=facebook
- https://regexlib.com/Search.aspx?k=wikipedia
https://www.regextester.com/ (this one’s very nice for editing and trying regex rules. I’ve at times often used it for grab-site warc archiving efforts)
It’s also probably a good idea to doublecheck the rules using YaCy’s own regex tester found at /RegexTest.html , just to be sure.
2 Likes
/CrawlStartExpert.html
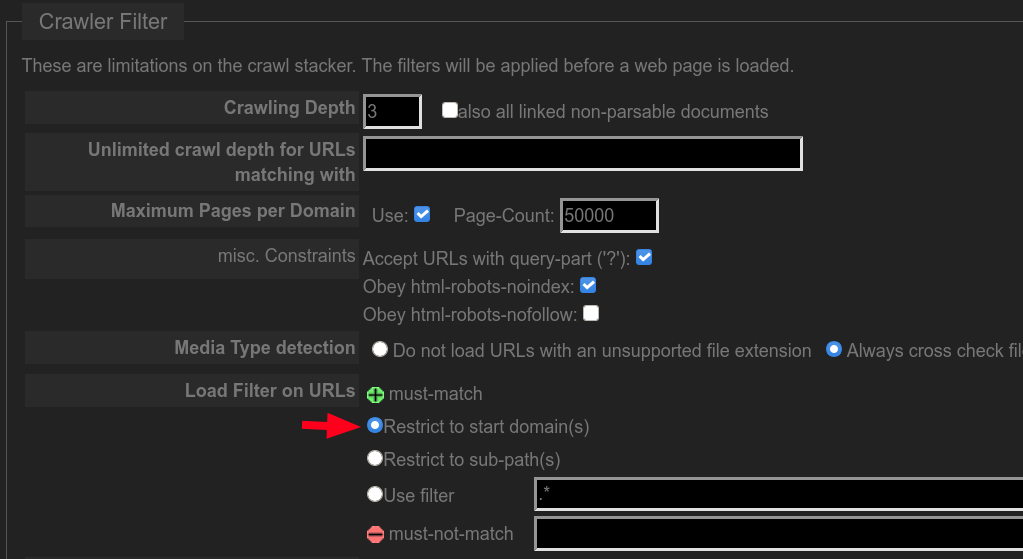
this will prevent crawler from going outside given list of domain(s) of desired start pages(, i think). Probably the easiest way without applying more advanced filtering.
Do any of these settings allow me to not index based on site categories such as adult web site, or sites that should not be visited by law? I am eager to get started and am studying to educate myself. Thank you for this great tool to put power back into the hands of the people.
One solution is to collect black lists from all the indexing nodes with URL categorizations and then allow the indexers to configure what will and will not index based on it. As the list grows, the community derived black list could become a very reliable source for using a black list.
Here is a possible starting point for Unix systems:
-
Download the below link to your ~/yacy/DATA/LISTS
Blacklists UT1 -
Unzipped the files:
cd ~yacy/DATA/LISTS/; for f in *.gz; do tar -xvf $f; done -
created my custom black list:
rm url.custom.blacklist.black; for f in */*/*; do cat $f >> url.custom.blacklist.black; done -
Specify it as my black list file
Startup and look for errors in the latest ./yacy/DATA/LOG/yacy*.log
I got multiple errors like these:
java.util.regex.PatternSyntaxException: Unmatched closing ‘)’ near index 52
banner/|/sponsor/|/event.ng/|/Advertisement/|adverts/)
java.util.regex.PatternSyntaxException: Unmatched closing ‘)’ near index 52
banner/|/sponsor/|/event.ng/|/Advertisement/|adverts/)
and had to remove multiple entries from the list. If anyone finds a streamlined way of fixing all the regular expression errors, please do share.
Please note this list gets frequently updated so just a starting point and I look forward to your findings, and feedback if this is a good starting point. (3million entries)
then start YaCy as before, and now you have a black list to filter on.
1 Like
With all respect; It would be 100% impossible for a software such as YaCy to keep up with any “should not be visited by law”. and what sites would classify as adult websites.
- What is lawful or not varies greatly both throughout time and geographical/regional at rapid pace.
- What is considered “Adult Content” likewise also varies greatly the same. Not to mention adult content sites pop up on The Internet literally at a rate of hundreds of thousands EACH second, and likewise dissapear at a frequency so rapid it would be insanity to even try to monitor it.
Expecting YaCy to have and maintain any sort of uniform and up-to-date knowledge of what is what of those two, would IMHO not only be wholly undesirable, but 100% against the idea.
If a certain domain/site and it’s contents is outlawed somewhere, then it is that judicial regions law responsibily to apply e.g nation- or region-wide DNS blocking of access that specific domain.
I bet there are numerous databases out there that you could implement as a blacklist. I simply blacklisted my yacy from crawling the largest ones like pornhub, xhamster etc, and e.g the *.xxx / *.sex / *.cam TLD domains. https://data.iana.org/TLD/tlds-alpha-by-domain.txt
Other than that, i simply don’t crawl with “Media” being on.
CENSORSHIP IS NOT A TASK FOR YaCY!!
and if it ever was, or became that, in any way shape form or fashion, I’d stop using it instantly and delete it, index and all.
… And Raylene is hot! ![]()
1 Like